Kaggle - London Bike Sharing (2) 데이터 전처리:이상치 제거
앞 내용에서 데이터 시각화 문제를 해결하자마자
바로 다시 에러 발생

이 부분이 제일 중요한 것 같은데..!!
>> 이상치 제거
시그마 제거, IQR 방법, k-means 군집 기반 제거 방법 등이 있다.
시그마 제거, IQR 제거 방법은 아래 블로그 참고할 예정 (지금은 한번 쭉 훑는게 목적이라 패스)
https://brave-greenfrog.tistory.com/13
kaggle 실습 - 아웃라이어(이상치) 제거
1. 3시그마 이상치 제거 3 시그마 이상치 제거란 ? 정규분포에서 데이터들이 ±3σ 안에 포함될 확률은 무려 99.7%인데 3 시그마 규칙이란 데이터가 ±3σ 밖에 존재할 확률은 0.3%이기 때문에 이 범위
brave-greenfrog.tistory.com
>> 코드
* 이상치 제거 함수 정의
def is_outliers(s): # 3시그마 이상치 제거
# 시그마 제거, IQR 방법 (boxplot사용)
# k-means 군집 제거 등...
lower_limit = s.mean() - (s.std()*3)
upper_limit = s.mean() + (s.std()*3)
return ~s.between(lower_limit, upper_limit)
# lower_limit 과 upper_limit 사이에 있지 않은 것들을 return 하라
# ~ 은 "조건을 만족하지 않는 경우 return하라" 라는 의미* 데이터 내 이상치 제거
위에서 정의한 is_outliers 함수를 사용하여 df 데이터의 이상치를 제거하고자 한다.
df_out = df[~df.groupby('hour')['cnt'].apply(is_outliers)]
df_out.dtypes>>

df.groupby('hour')를 하게 되면, df 데이터 안의 'hour' 칼럼에 대해 데이터를 grouping해준다.
예를 들어,
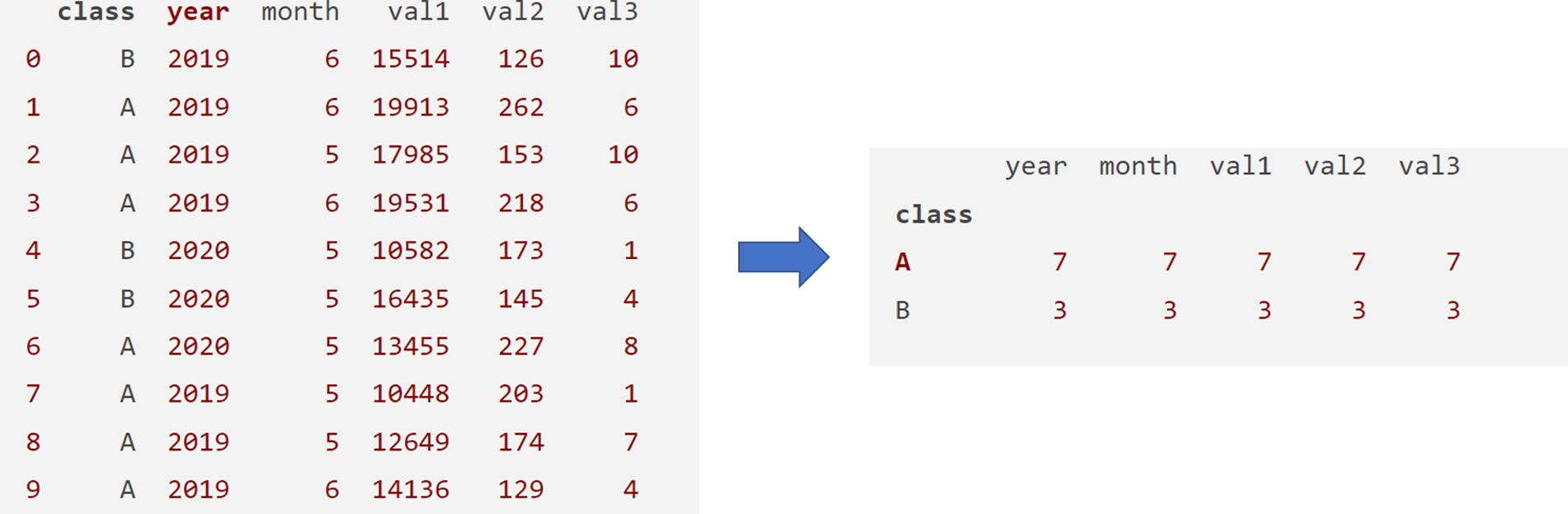
이 때. 오른쪽 데이터로 만들기 위한 코드는
df_out = df.groupby('class')
df_out을 위 예시처럼 보여주는 코드는
df_out.count()
* 학습 가능한 형태로의 타입 변환 (1)
위 데이터에서 weather_code, season, year, month, hour 정보를 학습에 사용할 것이기 때문에
학습에 용이한 형태인 'category'로 데이터 타입을 변환해준다.
# 분류를 위해 데이터를 카테고리화
df_out['weather_code'] = df_out['weather_code'].astype('category')
df_out['season'] = df_out['season'].astype('category')
df_out['year'] = df_out['year'].astype('category')
df_out['month'] = df_out['month'].astype('category')
df_out['hour'] = df_out['hour'].astype('category')
df_out.dtypes>>

* 학습 가능한 형태로의 타입 변환 (2)
이어서, 학습에 용이한 형태인 0과 1로의 데이터 타입을 바꿔주기 위해 dummy 데이터로 만들어 준다.
df_out = pd.get_dummies(df_out, columns=['weather_code','season','year','month','hour'])
df_out.head()>>
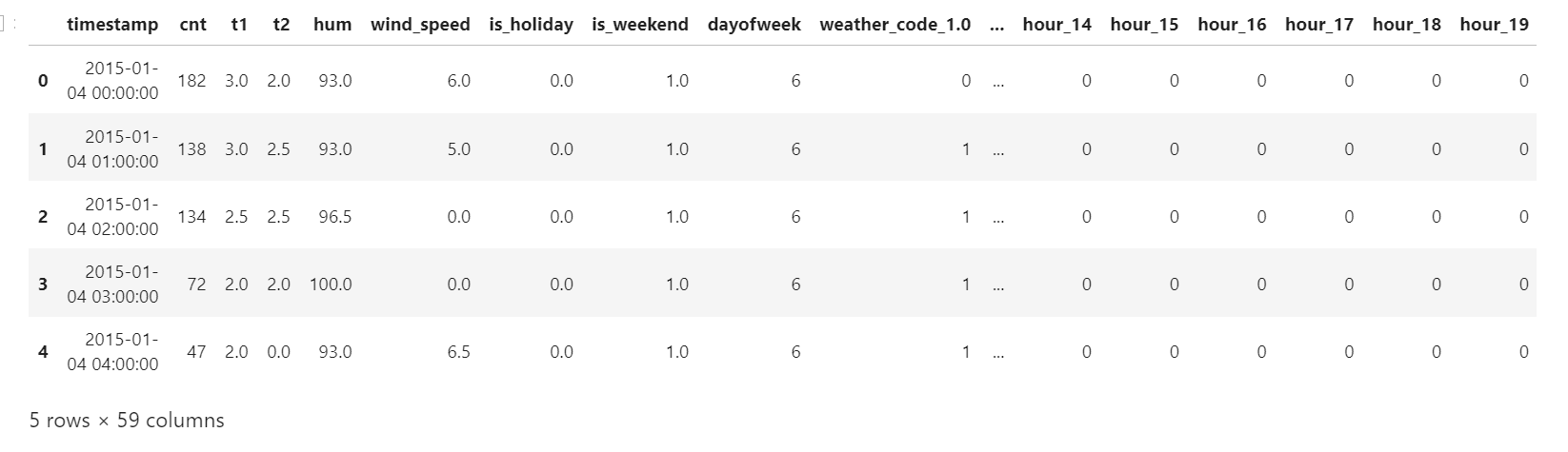
' weather_code2.0 ' 열 의 값 = 1이면
해당 행의 weather_code = 2.0 이었다는 말이다.
(에러 발생)
>> 데이터 내 이상치 제거 단계
df_out = df[~df.groupby('hour')['cnt'].apply(is_outliers)]
위 코드를 사용하면 다음과 같은 에러가 뜬다.
IndexingError: Unalignable boolean Series provided as indexer (index of the boolean Series and of the indexed object do not match).hour
0 0 True
24 True
48 True
72 True
95 True
Name: cnt, dtype: bool
df_out_ = ~df.groupby('hour')['cnt'].apply(is_outliers)
df_out_.head()의 출력값은 다음과 같고, 저 마지막 열의 True 때문에 생기는 문제인 것 같다..하 개박친다

.
.
.
다른 돌아가는 분의 코드를 돌려봤다..
그 환경에서는 돌아가고, 내 환경에서는 안 돌아간다.
import sys
sys.version위 코드를 입력해봤더니 돌아가는 환경은 3.6.6 이고, 내가 원래 쓰던 환경은 3.10 대였다. ㅎㅎ
3.6대 환경으로 맞추고 다시 시작..!